
Introduction
I am using KVM as my virtualisation platform. I now have enough virtual machines (VMs) to generate more CPU fan noise than I want to listen to. So I wanted to investigate whether LXC would make a suitable lightweight replacement and I want to learn about LXC.
Beware that the scripts referenced here may have changed during or since this page was written! That means that calling them as described below may actually not work! That is the nature of a development log!
Hard requirement: isolation
The libvirt documentation about isolation explains that for the isolation of:
- network: there is isolation only if the container has network interfaces
- filesystems: there is isolation only if the container has filesystems
- users and groups: there is isolation only if the container uses mapping
But there are additional things that need to be isolated:
- IPC
- used memory (stuff in host memory should not be accessible from the container)
- free memory (the container should not see more memory that it is allowed to)
- process trees
- devices (the container should not be able to mknod stuff and if the host mknods stuff for it then those devices should still not be accessible)
- this document provides some more ideas about what can be isolated
Hard requirement: libvirt-based management
Currently I use one DRBD-over-LV per VM, which obviates the normal cluster requirement for a shared filesystem while still allowing an even distribution of VMs across servers and providing redundancy for all hardware components.
This model exposes block devices, which provide a stable and clean way to interface to libvirt/KVM, although the devices are not under libvirt’s pool management facilities. This is a comfortable environment and one that hides the details of managing the underlying KVM virtualisation platform.
Since one possible outcome of this investigation is that I gradually migrate VMs from KVM to LXC within one cluster, then being able to use libvirt in the future is essential.
Hard-requirement: DRBD-backed storage volumes
DRBD provides cheap redundancy with low management overhead. So I want to stick with it.
Soft requirement: use of libvirt for storage management
As just mentioned, I currently cannot use libvirt’s pool management, but it would be nice if I could.
Soft requirement: OS-level containers
In order to provide a standard environment on all physical machines (PMs), VMs and containers, I want the OS to be my unit of deployment; I do not want the application – Docker-style – to be my unit of deployment.
Prologue
I did not want to contaminate my PM virtualisation servers (fiori and torchio) so I used a KVM VM (testaroli) to experiment on. I Installed Debian 10 on this VM.
Installing LXC
- As per Debian’s LXC documentation, I ran:
apt-get install -y lxc libvirt0 libpam-cgfs bridge-utils uidmap
- I added a new connection to virt-manager: remote host testaroli.pasta.net, type: LXC.
- To support using virsh I also ran in a terminal:
# if working remotely export LIBVIRT_DEFAULT_URI=lxc+ssh://root@testaroli.pasta.net/ # if working locally export LIBVIRT_DEFAULT_URI=lxc:///
Exploring isolation
- I use virt-manager to create a new application container named vm1 to run the default application (
/bin/sh), no network interfaces (if you have defined networks then you will actually have to remove an interface), the default 1GB RAM and no filesystems (but note that one filesystem mapping is automatically created when the container is started) and no user mapping:
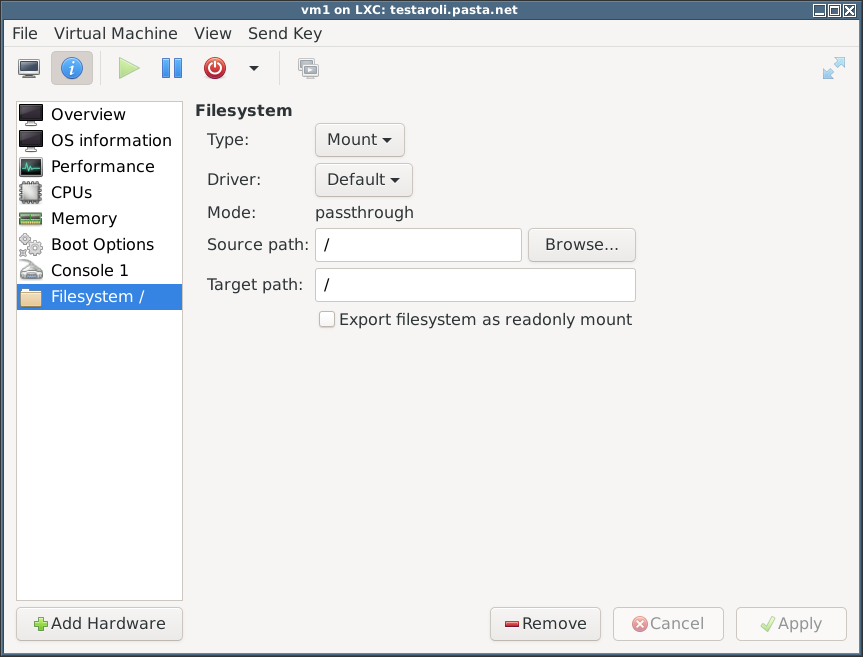
- To test IPC isolation I ran this in the host:
testaroli# perl -e 'use IPC::SysV qw(IPC_CREAT); $IPC_KEY = 1234; $id = semget($IPC_KEY, 10, 0666 | IPC_CREAT);' testaroli# ipcs -s ------ Semaphore Arrays -------- key semid owner perms nsems 0x000004d2 360448 root 666 10 testaroli#
(that code is taken straight from the perlipc(1) man page) and in the container I ran:
root@vm1:/# ipcs -s ------ Semaphore Arrays -------- key semid owner perms nsems root@vm1:/#
From that I concluded that there is IPC isolation by default.
- To test free memory isolation I ran the following in the host:
testaroli# head -1 /proc/meminfo MemTotal: 4039828 kB testaroli#
and then this in the container:
/bin/sh: 0: can't access tty; job control turned off # / exec bash root@vm1:/# head -1 /proc/meminfo MemTotal: 4039828 kB root@vm1:/#
From this I concluded there was no free memory isolation! It looks like this is due to a bug. See Questions below.
- To test process isolation I ran the following in the host:
testaroli# ps -ef | wc -l 133 testaroli# sleep 300 & [1] 3736 testaroli#
and then this in the container:
/bin/sh: 0: can't access tty; job control turned off # / exec bash root@vm1:/# ps -ef | wc -l 4 root@vm1:/# kill 3736 sh: can't kill pid 3736: No such process root@vm1:/# ls /proc/3736 ls: /proc/3736: No such file or directory root@vm1:/#
From this I concluded there was process isolation.
- To test device isolation I ran the following in the host:
testaroli# ls -lL /dev/vg0/root brw-rw---- 1 root disk 253, 0 May 7 14:51 /dev/vg0/root testaroli# mknod /tmp/vg0-root-host b 253 0 testaroli# chmod 666 /tmp/vg0-root-host testaroli#
and then this in the container:
/bin/sh: 0: can't access tty; job control turned off # / exec bash root@vm1:/# mknod /tmp/vg0-root-container b 253 0 mknod: /tmp/vg0-root: Operation not permitted root@vm1:/# ls -ld /tmp/vg0-root-host brw-r--r-- 1 root root 253, 0 May 10 16:28 /tmp/vg0-root-host root@vm1:/# dd if=/tmp/vg0-root-host of=/dev/null bs=1M count=1 dd: failed to open '/tmp/vg0-root-host': Permission denied root@vm1:/# lspci 00:00.0 Host bridge: Intel Corporation 82G33/G31/P35/P31 Express DRAM Controller 00:01.0 VGA compatible controller: Red Hat, Inc. QXL paravirtual graphic card (rev 04) 00:02.0 PCI bridge: Red Hat, Inc. QEMU PCIe Root port ... root@vm1:/#
and then again on the host:
testaroli# rm /tmp/vg0-root-host testaroli#
From this I concluded that there is limited device isolation; devices appear to be visible but not readable or writable.
- To test network isolation, I first ran this in the container to demonstrate that by default there is no isolation:
root@vm1:/dev# echo 'nameserver 8.8.8.8' > /etc/resolv.conf root@vm1:/dev# ping -c 3 www.de PING www.de (103.224.182.245) 56(84) bytes of data. 64 bytes from lb-182-245.above.com (103.224.182.245): icmp_seq=1 ttl=43 time=182 ms 64 bytes from lb-182-245.above.com (103.224.182.245): icmp_seq=2 ttl=43 time=178 ms 64 bytes from lb-182-245.above.com (103.224.182.245): icmp_seq=3 ttl=43 time=175 ms ^C --- www.de ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 3ms rtt min/avg/max/mdev = 175.355/178.502/181.697/2.634 ms root@vm1:/dev#
and then used virt-manager on fiori to add a non-NAT-ed network to testaroli and added an interface to this network to the container:
# exec bash root@vm1:/# ifconfig eth0 192.168.100.131 netmask 255.255.255.0 up root@vm1:/# nmap -sP 192.168.100.0/24 Nmap scan report for 192.168.100.1 Host is up (0.000046s latency). MAC Address: 52:54:00:56:EB:8C (QEMU virtual NIC) Nmap scan report for vm1.dummynet (192.168.100.131) Host is up. Nmap done: 256 IP addresses (2 hosts up) scanned in 16.77 seconds root@vm1:/# route add -net default gw 192.168.100.1 root@vm1:/# ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. ^C root@vm1:/#
Then I shutdown the container and removed its network interface.
From this I concluded that adding network interfaces did provide network isolation. - From this point on the remaining checks were best done with a filesystem dedicated to the container.
- On the host I created a container-specific subdirectory and added that as the root filesystem:
testaroli# mkdir /var/lib/libvirt/images/vm1 testaroli#
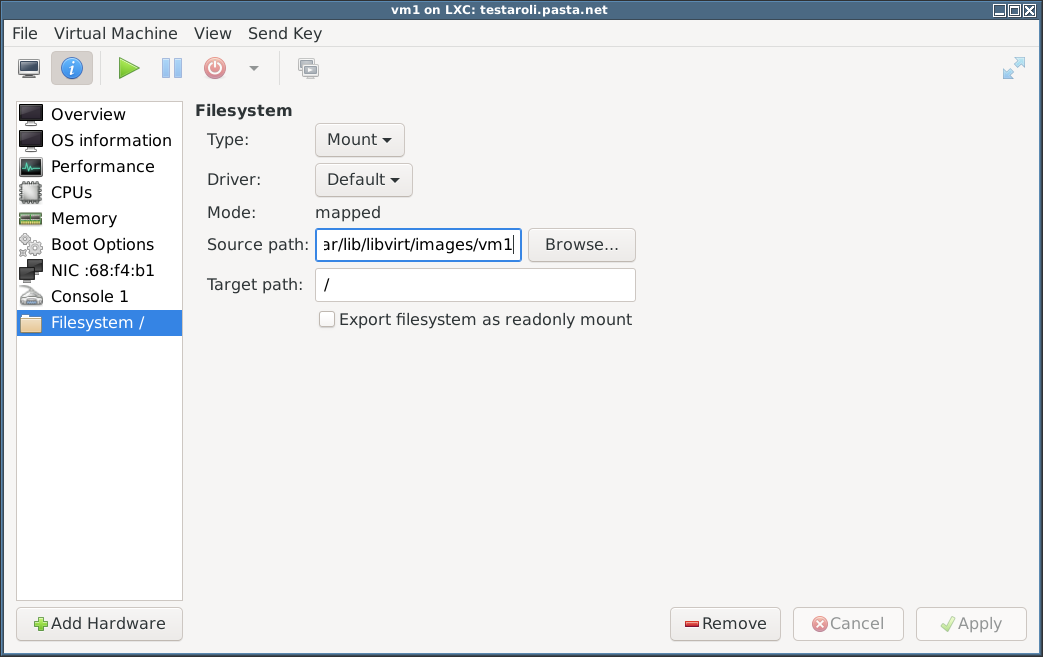
but – to be expected really – that fails to start because/bin/shdoes not exist within it:libvirt.libvirtError: internal error: guest failed to start: Failure in libvirt_lxc startup: cannot find init path '/bin/sh' relative to container root: No such file or directory
and after putting a (static) shell in place:
testaroli# mkdir /var/lib/libvirt/images/vm1/bin testaroli# cp /usr/bin/busybox /var/lib/libvirt/images/vm1/bin/sh testaroli#
and then on the container:
/ # find / -xdev | wc -l 7 / #
From this I concluded that adding filesystems did provide filesystem isolation.
- To test used memory isolation I ran the following in the host
testaroli# mkdir /var/lib/libvirt/images/vm1/dev2 testaroli# mknod /var/lib/libvirt/images/vm1/dev2/mem c 1 1 testaroli#
and then ran this is the host:
for I in {1..10}; do dd if=/dev/mem bs=1M count=1 2>/dev/null | md5sum sleep 1 doneand this in the container:
for I in 1 2 3 4 5 6 7 8 9 10; do dd if=/dev2/mem bs=1M count=1 2>/dev/null | md5sum sleep 1 done(Note avoidance of
{X..Y}, which is not supported by BusyBox’s shell, and use of /dev2, as the container’s /dev appears not to be accessible from the host.)From the differing checksums I concluded that there is used memory isolation.
- To test UID/GID isolation I used virt-manager to enable user namespace:
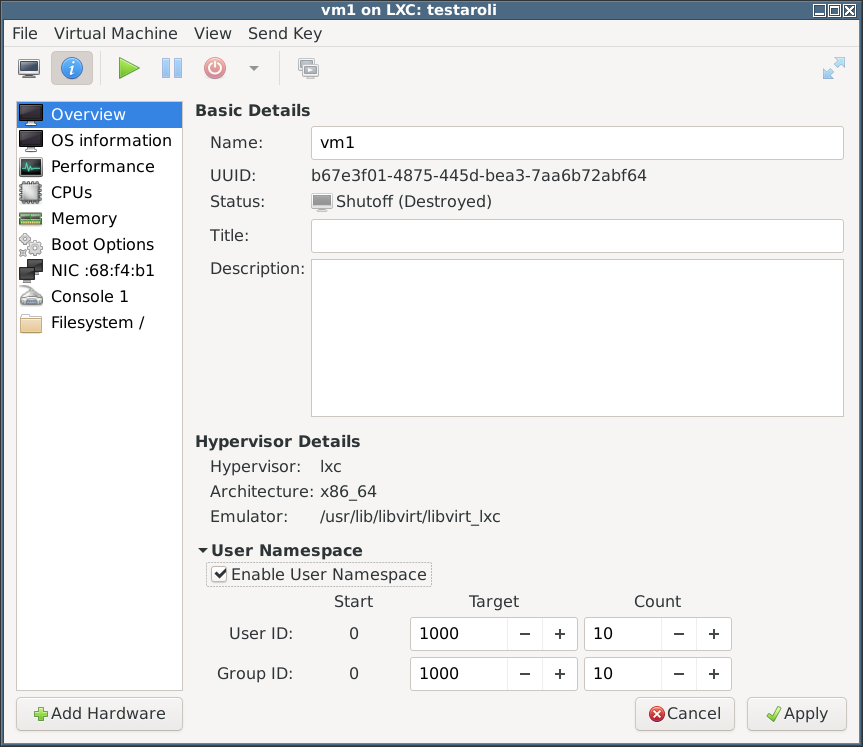
(In reviewing this page, I believe that screenshot above is wrong: it shows a NIC but the error below only appears when there is no NIC.) - However, attempting to start the container resulted in this:
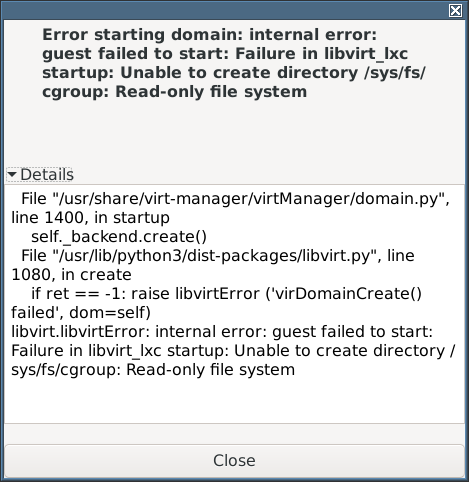
This problem is described by Richard Weinberger and Daniel Berrange:> > Fact is that commit a86b6215a74 is broken.
> > We could also refuse to create container with userns
> > enabled but netns disabled…
> …
Yes, if we are unable to figure out how to make this work, then we should report VIR_ERR_CONFIG_UNSUPPORTED for the combination of private userns + shared netnsSo I re-added the network interface, after which the container would start without problems.
- I tested UID/GID isolation by running this in the host:
testaroli# mkdir /var/lib/libvirt/images/vm1/tmp testaroli# chmod 1777 /var/lib/libvirt/images/vm1/tmp testaroli# touch /var/lib/libvirt/images/vm1/tmp/y testaroli#
and this in the container:
/ # touch /tmp/x / # ls -l /tmp/ total 0 -rw-r--r-- 1 0 0 0 May 19 12:47 x -rw-r--r-- 1 65534 65534 0 May 19 11:46 y / #
and then this in the host:
testaroli# ls -l /var/lib/libvirt/images/vm1/tmp total 0 -rw-r--r-- 1 1000 1000 0 May 19 14:47 x -rw-r--r-- 1 root root 0 May 19 13:46 y testaroli#
From this I concluded that enabling user namespaces does add isolation but see Questions below.
Storing container filesystems in images in a type ‘fs’ pool
Due to the userns-enabled-and-netns-disabled issue described earlier, these experiments were done with a userns-enabled-and-netns-enabled container.
- On fiori/torchio I allocated a 100GB DRBD volume and gave it to testaroli as vdb.
- On testaroli I ran:
testaroli# pvcreate /dev/vdb testaroli# vgcreate vg1 /dev/vdb testaroli# lvcreate --extents=100%FREE --name=containers vg1 testaroli# mkfs -t ext4 /dev/vg1/containers testaroli#
- I left it unmounted and used virt-manager to created a storage pool of type ‘fs’ (preformatted block device) out of it; this way libvirt could manage the mounting/unmounting.
- But the pool can only be mounted on one of my virtualisation servers so that would mean all VMs (in the pool) would have to be run on the same virtualisation server, which is not what I want.
- Alternatively, I could have one pool per virtualisation server but this is also not flexible regarding which VMs could be run where.
- Option rejected without further testing. Cleaned up.
Storing container filesystems in a ‘file’ filesystem
Due to the userns-enabled-and-netns-disabled issue described earlier, these experiments were done with a userns-enabled-and-netns-enabled container.
I wanted to do a ‘block’ type filesystem for a single container. This would have required create a DRBD-over-LV device again, but not to act as a pool, but for a single container. However, as a first step I though ot testing a ‘file’ filesystem. If this worked then hopefully a ‘block’ type volume would work.
- On testaroli I ran:
testaroli# dd if=/dev/zero of=/var/lib/libvirt/images/vm1.img bs=1M count=1000 testaroli# mkfs -t ext4 /var/lib/libvirt/images/vm1.img testaroli# losetup /dev/loop0 /var/lib/libvirt/images/vm1.img testaroli# mount /dev/loop0 /mnt testaroli# mkdir /mnt/bin testaroli# cp /bin/busybox /mnt/bin/sh testaroli# umount /mnt testaroli# losetup -d /dev/loop0 testaroli#
- I added a filesystem to the container:
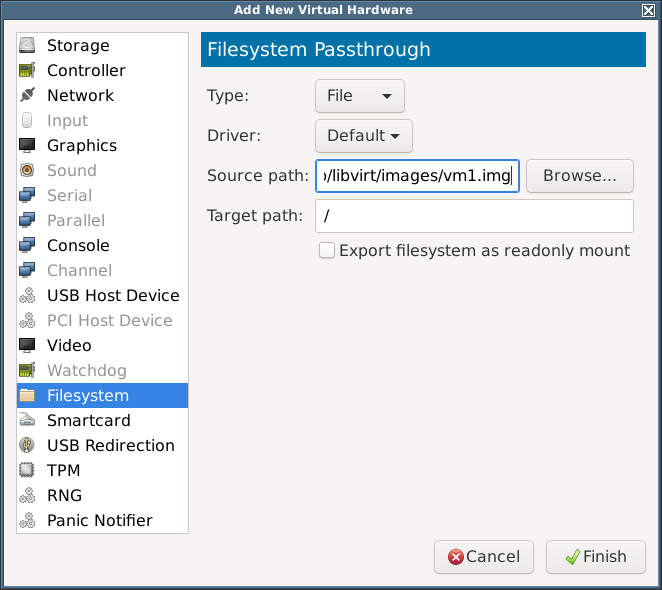
- I tried to start the container but got:
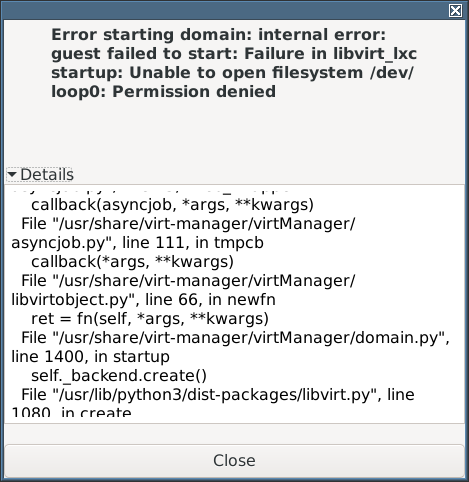
- I tried adding /dev/loop0 directly as a block device:
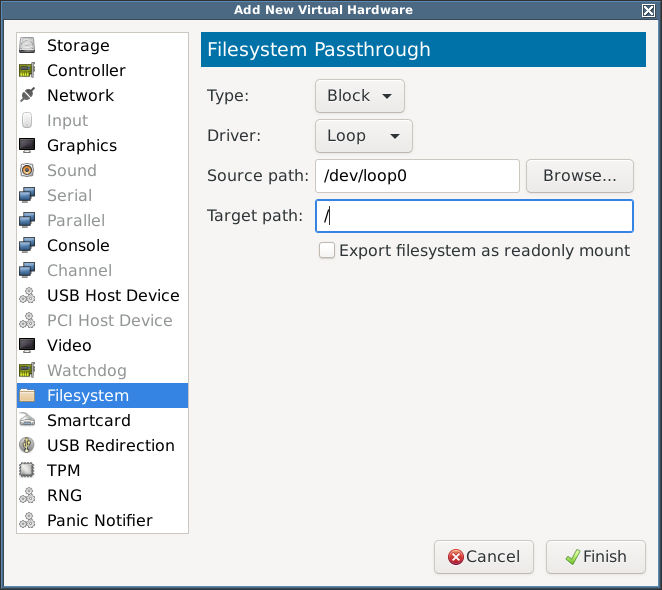
- I tried to start the container but got:
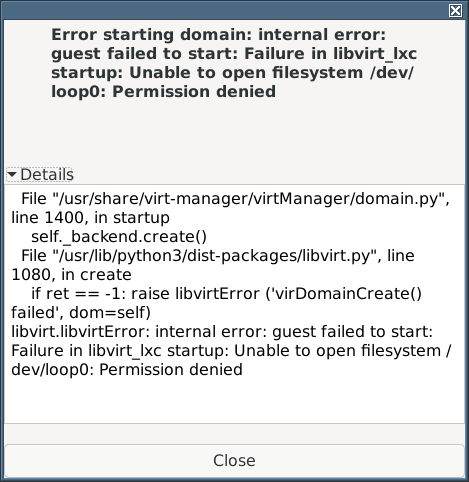
- This looks similar to this bug, although the link at the bottom of the page seems less relevant.
- If I disable user-namespace (under Overview) and revert to using the image file rather than the loop device, then it works, but I really do want to use unprivileged containers.
- Option reject. Cleaned up. Added todo-list item to try the same thing on a Debian testing KVM VM.
Storing container filesystems in a pool-less LV
Due to the userns-enabled-and-netns-disabled issue described earlier, these experiments were done with a userns-enabled-and-netns-enabled container.
- Add a 30GB ‘containers’ device to testaroli by running this:
lagane# ~/opt/roottools/bin/pasta-virsh-vol-create-as testaroli_vm1 30 fiori lagane#
- Attach it to testaroli by running:
fiori# virsh attach-disk testaroli /dev/drbd_testaroli_vm1 vdb fiori#
- On testaroli allocate it to a new VG in LVM:
testaroli# pvcreate /dev/vdb testaroli# vgcreate vg_vm1 /dev/vdb testaroli#
- Create a pool out of the VG (don’t try this with virt-manager; it gets very confused):
testaroli# virsh pool-define-as vm1 --type=logical --target=/dev/vm1 testaroli# virsh pool-start vm1 testaroli#
- Use virt-manager to create a 1GB volume in the vm1 storage pool.
- Allocate this volume as a filesystem og type Block and driver Loop and target path /.
- Make a filesystem on the device, mount it on /mnt, create /mnt/bin, copy busybox to /mnt/bin/sh, unmount it.
- If username namespace is enabled then startup will fail (even with a network device) but if it is not enabled then startup will succeed. But that is an privileged container again!
- Reject.
- Clean up all the way to removing the pool but not the LV.
- Make sure the LV is active:
testaroli# lvs ... vm1_root vm1 -wi------- 1.00g testaroli# lvchange -a y /dev/vm1/vm1_root testaroli#
- Mount the volume:
testaroli# mount /dev/vm1/vm1_root /var/lib/libvirt/images/vm1 testaroli#
- Add a filesystem to the VM of type Mount, driver Default.
- Start it with username space enabled.
- It works!
- On the host run:
testaroli# cd /var/lib/libvirt/images/vm1 testaroli# chown 1000:1000 . * bin/* testaroli#
(1000 is the beginning of the user namespace.)
- Then on the host this can be done:
/ # ls -al total 20 drwxr-xr-x 9 0 0 4096 May 23 17:30 . drwxr-xr-x 9 0 0 4096 May 23 17:30 .. drwxr-xr-x 2 65534 65534 4096 May 23 17:16 bin drwxr-xr-x 3 0 0 320 May 23 17:28 dev drwx------ 2 65534 65534 16384 May 23 17:16 lost+found dr-xr-xr-x 165 65534 65534 0 May 23 17:28 proc dr-xr-xr-x 13 65534 65534 0 May 23 17:28 sys / # mkdir /tmp / # chmod 1777 /tmp / #
Switch to Debian testing
The checks above need to be repeated on Debian 11, which, at the time of writing, was not released yet. However, Debian 11 RC2 was out and could be used to test.
Unfortunatey, I got a bit diverted porting PCMS to Debian 11. Furthermore, that necessitated some changes to my Subversion repositories to support password-less svn-updates.
Finally, I got unblocked, cloned all the above content below … and continued!
Prologue
I did not want to contaminate my PM virtualisation servers (fiori and torchio) so I used a KVM VM (testaroli) to experiment on. I Installed Debian 11 RC2 on this VM.
Installing LXC
- As per Debian’s LXC documentation, I ran:
apt-get install -y lxc libvirt0 libpam-cgfs bridge-utils uidmap libvirt-clients \ netcat-openbsd libvirt-daemon libvirt-daemon-system - In order to text Debian 11’s LXC using Debian 11’s virt-manager I ran:
apt-get -y install virt-manager
(Any interaction, screenshots, etc with virt-manager now refers to Debian 11’s virt-manager.)
- I added a new connection to virt-manager: local, type: LXC.
- To support using virsh I also ran in a terminal:
# if working remotely export LIBVIRT_DEFAULT_URI=lxc+ssh://root@testaroli.pasta.net/ # if working locally export LIBVIRT_DEFAULT_URI=lxc:///
Exploring isolation
- I use virt-manager to create a new application container named vm1 to run the default application (
/bin/sh), no network interfaces (if you have defined networks then you will actually have to remove an interface), the default 1GB RAM and no filesystems (but note that one filesystem mapping is automatically created when the container is started) and no user mapping:
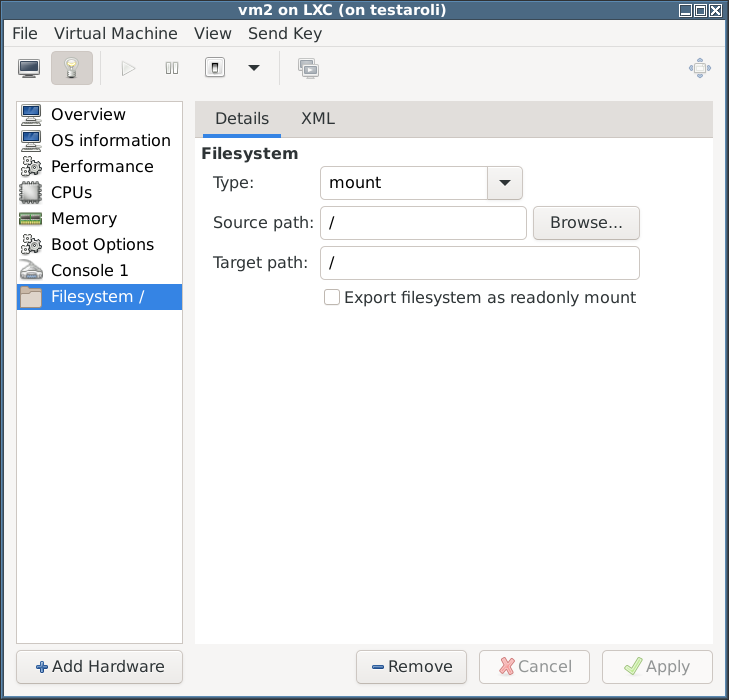
- In the VM I ran:
/bin/sh: 0: can't access tty; job control turned off # exec bash root@vm2:/#
- To test IPC isolation I ran this in the host:
testaroli# perl -e 'use IPC::SysV qw(IPC_CREAT); $IPC_KEY = 1234; $id = semget($IPC_KEY, 10, 0666 | IPC_CREAT);' testaroli# ipcs -s ------ Semaphore Arrays -------- key semid owner perms nsems 0x000004d2 1 root 666 10 testaroli#
(that code is taken straight from the perlipc(1) man page) and in the container I ran:
# ipcs -s ------ Semaphore Arrays -------- key semid owner perms nsems #
From that I concluded that there is IPC isolation by default.
- To test free memory isolation I ran the following in the host:
testaroli# head -1 /proc/meminfo MemTotal: 4024000 kB testaroli#
and then this in the container:
root@vm2:/# head -1 /proc/meminfo MemTotal: 1048576 kB root@vm2:/#x
From this I concluded there is memory isolation by default, i.e. this bug has been fixed in Debian 11 RC2.
- To test process isolation I ran the following in the host:
testaroli# ps -ef | wc -l 125 testaroli# sleep 300 & [1] 8585 testaroli#
and then this in the container:
root@vm2:/# ps -ef | wc -l 4 root@vm2:/# kill 8585 bash: kill: (8585) - No such process root@vm2:/# ls /proc/8585 ls: cannot access '/proc/8585': No such file or directory root@vm2:/#
From this I concluded there was process isolation.
- To test device isolation I ran the following in the host:
testaroli# ls -lL /dev/vg0/root brw-rw---- 1 root disk 253, 1 Jul 15 11:07 /dev/vg0/root testaroli# mknod /tmp/vg0-root-host b 253 0 testaroli# chmod 666 /tmp/vg0-root-host testaroli#
and then this in the container:
root@vm2:/# mknod /tmp/vg0-root-container b 253 0 mknod: /tmp/vg0-root-container: Operation not permitted root@vm2:/# ls -ld /tmp/vg0-root-host brw-rw-rw- 1 root root 253, 0 Jul 15 12:04 /tmp/vg0-root-host root@vm2:/# dd if=/tmp/vg0-root-host of=/dev/null bs=1M count=1 dd: failed to open '/tmp/vg0-root-host': Permission denied root@vm2:/# lspci 00:00.0 Host bridge: Intel Corporation 82G33/G31/P35/P31 Express DRAM Controller 00:01.0 VGA compatible controller: Red Hat, Inc. QXL paravirtual graphic card (rev 04) 00:02.0 PCI bridge: Red Hat, Inc. QEMU PCIe Root port 00:02.1 PCI bridge: Red Hat, Inc. QEMU PCIe Root port ... root@vm2:/#
and then again on the host:
testaroli# rm /tmp/vg0-root-host testaroli#
From this I concluded that there is limited device isolation; devices appear to be visible but not readable or writable.
- To test network isolation, I first ran this in the container to demonstrate that by default there is no isolation:
root@vm2:/# echo 'nameserver 8.8.8.8' > /etc/resolv.conf root@vm2:/# ping -c 3 www.de ping: socket: Address family not supported by protocol PING www.de (103.224.182.245) 56(84) bytes of data. 64 bytes from lb-182-245.above.com (103.224.182.245): icmp_seq=1 ttl=45 time=173 ms 64 bytes from lb-182-245.above.com (103.224.182.245): icmp_seq=2 ttl=45 time=174 ms 64 bytes from lb-182-245.above.com (103.224.182.245): icmp_seq=3 ttl=45 time=174 ms --- www.de ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2003ms rtt min/avg/max/mdev = 173.399/173.768/174.396/0.445 ms root@vm2:/#
and then used virt-manager on fiori to add a non-NAT-ed network to testaroli and added an interface to this network to the container:
# exec bash root@vm2:/# ifconfig eth0 192.168.100.131 netmask 255.255.255.0 up root@vm2:/# nmap -sP 192.168.100.0/24 Starting Nmap 7.80 ( https://nmap.org ) at 2021-07-15 13:02 CEST Nmap scan report for 192.168.100.1 Host is up (0.000057s latency). MAC Address: 52:54:00:35:65:F7 (QEMU virtual NIC) Nmap scan report for 192.168.100.131 Host is up. Nmap done: 256 IP addresses (2 hosts up) scanned in 28.04 seconds root@vm2:/# route add -net default gw 192.168.100.1 root@vm2:/# ping 8.8.8.8 ping: socket: Address family not supported by protocol PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. From 192.168.100.1 icmp_seq=1 Destination Port Unreachable From 192.168.100.1 icmp_seq=2 Destination Port Unreachable From 192.168.100.1 icmp_seq=3 Destination Port Unreachable From 192.168.100.1 icmp_seq=4 Destination Port Unreachable ^C --- 8.8.8.8 ping statistics --- 4 packets transmitted, 0 received, +4 errors, 100% packet loss, time 3058ms root@vm2:/#
Then I shutdown the container and removed its network interface.
From this I concluded that adding network interfaces did provide network isolation. - Note that above, in the ping outputs, both the VM and the host said:
ping: socket: Address family not supported by protocol
This seems to be due to a recently-introduced bug in ping. Using option
-4will avoid the warning. - On the host I created a container-specific subdirectory and added that as the root filesystem:
testaroli# mkdir /var/lib/libvirt/images/vm2 testaroli#
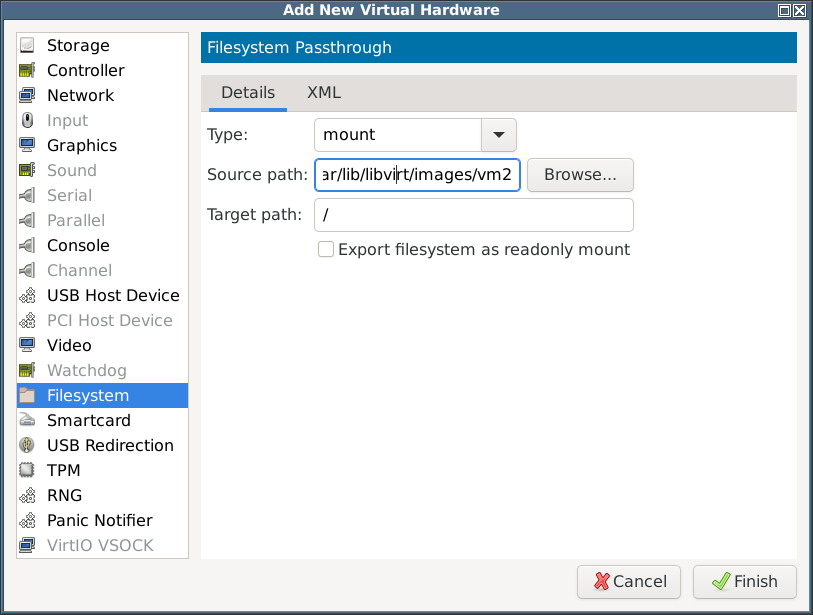
but – to be expected really – that fails to start because/bin/shdoes not exist within it:Error starting domain: internal error: guest failed to start: Failure in libvirt_lxc startup: cannot find init path '/bin/sh' relative to container root: No such file or directory
and after putting a (static) shell in place:
testaroli# mkdir /var/lib/libvirt/images/vm2/bin testaroli# cp /usr/bin/busybox /var/lib/libvirt/images/vm2/bin/sh testaroli#
and then on the container:
BusyBox v1.30.1 (Debian 1:1.30.1-6+b2) built-in shell (ash) Enter 'help' for a list of built-in commands. /bin/sh: can't access tty; job control turned off / # find / -xdev | wc -l 7 / #
From this I concluded that adding filesystems did provide filesystem isolation.
- (Test of the isolation of used memory removed; I believe this is a redundant test.)
- To test UID/GID isolation, I went back to the most basic container without network interfaces:
 then I started the container and inside it ran:
then I started the container and inside it ran:
root@vm2:/# touch /tmp/xxx root@vm2:/# ls -ld /tmp/xxx -rw-r--r-- 1 root root 0 Jul 15 15:21 /tmp/xxx root@vm2:/#
and compared the ownership of that new file as seen from the host:
testaroli# ls -ld /tmp/xxx -rw-r--r-- 1 root root 0 Jul 15 15:21 /tmp/xxx testaroli#
- So by default there is no user namespace isolation. Stop the container.
- But there is a problem: compare the screenshot above with the one from Debian 10: the one from Debian 10 has widgets for configuring user namespaces, but the one from Debian 11 does not. However, the same can done with virt-xml.
- Run:
testaroli# virt-xml vm2 --edit --idmap uid_start=0,uid_target=1000,uid_count=10,gid_start=0,gid_target=1000,gid_count=10 Domain 'vm2' defined successfully. testaroli#
(Note that in Debian 10’s virt-manager it is possible to configure user namespaces; in Debian 11 RC2’s it was not possible because the relevant widgets were not present in the GUI; in Debian 11 RC2 plus a couple of weeks (virt-manager 1:3.2.0-3) it was again possible to configure user namespaces..
- Run:
testaroli# virsh start vm2 error: Failed to start domain 'vm2' error: internal error: guest failed to start: Failure in libvirt_lxc startup: Failed to mount /sys on /sys type sysfs flags=0x100e: Invalid argument testaroli#
It could be that this is the userns/netns problem described in the Debian 10 section above. So I added a NIC and tried to start it again:
testaroli# virsh start vm2 Domain 'vm2' started testaroli#
and repeating the
touch+ls -ldcheck now in the container:root@vm2:/# touch /tmp/ttt root@vm2:/# ls -ld /tmp/ttt -rw-r--r-- 1 root root 0 Jul 15 15:38 /tmp/ttt root@vm2:/#
and in the host:
testaroli# ls -ld /tmp/ttt -rw-r--r-- 1 1000 1000 0 Jul 15 15:38 /tmp/ttt testaroli#
Great!
- From this I concluded that enabling user namespaces does add isolation but see Questions below.
Storing container filesystems in images in a type ‘fs’ pool
Due to the userns-enabled-and-netns-disabled issue described earlier, these experiments were done with a userns-enabled-and-netns-enabled container.
Ultimately, I do not want to use this storage configuration, but I do want to test one step at at time!
- On fiori/torchio I allocated a 100GB DRBD volume and gave it to testaroli as vdb.
- On testaroli I ran:
testaroli# pvcreate /dev/vdb testaroli# vgcreate vg1 /dev/vdb testaroli# lvcreate --extents=100%FREE --name=containers vg1 testaroli# mkfs -t ext4 /dev/vg1/containers testaroli#
- I left it unmounted and used virt-manager to created a storage pool with name ‘pool1’, of type ‘fs’ (preformatted block device) out of it; this way libvirt could manage the mounting/unmounting. The mountpoint was to be /var/lib/libvirt/images/pool1.
- But the pool can only be mounted on one of my virtualisation servers so that would mean all VMs (in the pool) would have to be run on the same virtualisation server, which is not what I want.
- Alternatively, I could have one pool per virtualisation server but this is also not flexible regarding which VMs could be run where.
- Option rejected without further testing. Cleaned up.
Storing container filesystems in a ‘file’ filesystem
Due to the userns-enabled-and-netns-disabled issue described earlier, these experiments were done with a userns-enabled-and-netns-enabled container.
I wanted to do a ‘block’ type filesystem for a single container. This would have required create a DRBD-over-LV device again, but not to act as a pool, but for a single container. However, as a first step I though ot testing a ‘file’ filesystem. If this worked then hopefully a ‘block’ type volume would work.
- On testaroli I ran:
testaroli# dd if=/dev/zero of=/var/lib/libvirt/images/vm2.img bs=1M count=1000 testaroli# mkfs -t ext4 /var/lib/libvirt/images/vm2.img testaroli# losetup /dev/loop0 /var/lib/libvirt/images/vm2.img testaroli# mount /dev/loop0 /mnt testaroli# mkdir /mnt/bin testaroli# cp /bin/busybox /mnt/bin/sh testaroli# umount /mnt testaroli# losetup -d /dev/loop0 testaroli#
- I added a filesystem to the container:
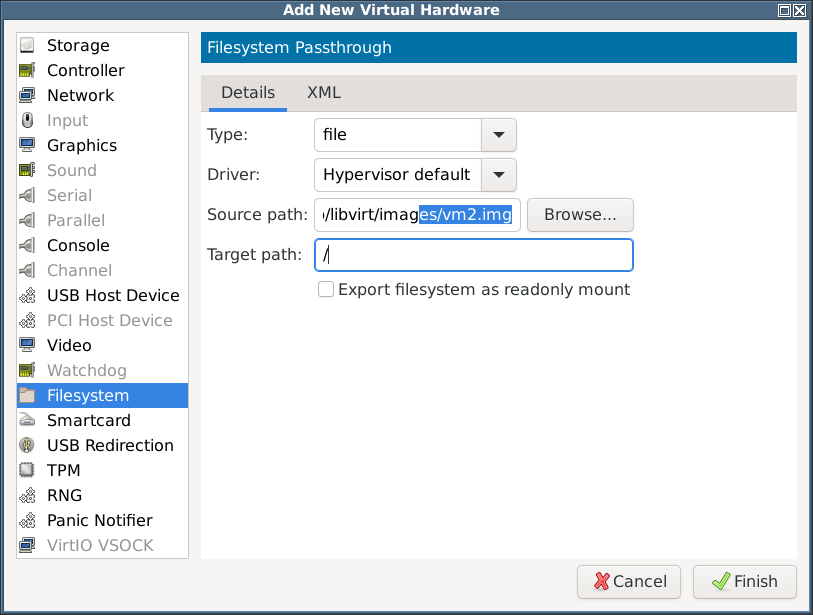
- I tried to start the container but got:
testaroli# virsh start vm2 error: Failed to start domain 'vm2' error: internal error: guest failed to start: Failure in libvirt_lxc startup: Failed to create /run/libvirt/lxc/vm2.root: Permission denied testaroli#
(Remember that user namespaces are still enabled.)
- I’m certain that disabling user namespaces would make this work, but username spaces is critical for security. Option reject. Cleaned up.
Other investigations
Other investigations show that NFS won’t work in unprivileged containers.
It is very well documented that privileged containers are not secure.
Conclusions #1
- I need to rethink volume management
- I could use it only for applications with no NFS requirements
Storage for OS containers
If, at the end of this investigation, I decide to use libvirt+LXC, then I would have a large amount of free space on fiori/torchio available to allocate to containers.
For testing on testaroli, I allocate a large DRBD-over-LV-based device on fiori, attach it to testaroli and prepare to allocate it to containers.
- On fiori/torchio I allocated a 100GB DRBD volume called drbd_testaroli_containers and gave it to testaroli as vdb.
- On testaroli I ran:
testaroli# pvcreate /dev/vdb testaroli# vgcreate vg1 /dev/vdb testaroli#
Storage for a particular OS container
If, at the end of this investigation, I decide to use libvirt+LXC, then I would allocate an OS-sized LV on fiori and torchio, put a DRBD device on it and – most import! – mount it manually (as libvirt won’t be able to, as it will run an unprivileged container).
For testing on testaroli, I allocate an OS-sized LV, put a filesystem on it and – most import! – mount it manually (as libvirt won’t be able to, as it will run an unprivileged container).
- On testaroli I ran:
lvcreate --size=15g --name=vm3_root vg1 mkfs -t ext4 /dev/vg1/vm3_root
Pools?
At this point I wondered: though libvirt+LXC cannot start volumes for an unprivileged container (because of the give-up-root-privileges-before-mount problem described above), it can probably start a pool, which is really not VM/container-specific, but which I could make to be container- or container-fs-specific.
If I made per-container pools based on the OS-sized LV (or DRBD-over-LV if investigation outcome positive) then I could put disk images inside it (which would have to be manually mounted because …).
Pools test #1
- Rename the just-created LV to be container-specific rather than container-fs-specific:
lvrename /dev/vg1/vm3_root /dev/vg1/vm3
- Put a filesystem on it:
mkfs -t ext4 /dev/vg1/vm3
- Allocate that formatted volume to a pool:
virsh pool-define-as --name=vm3 --type=fs --source-dev=/dev/vg1/vm3 --target=/var/lib/libvirt/images/vm3 virsh pool-start vm3
(That will also start the pool, as illustrated by a
mountordfcall.) - Create a disk image inside the pool ready for a simple test application container:
dd if=/dev/zero of=/var/lib/libvirt/images/vm3/root.img bs=1M count=10240 mkfs -t ext4 /var/lib/libvirt/images/vm3/root.img virsh pool-refresh vm3 mount /var/lib/libvirt/images/vm3/root.img /mnt mkdir /mnt/bin cp /bin/busybox /mnt/bin/sh chown -R 1000:1000 /mnt/ umount /mnt
- Create a simple application container as a test, use the virt-xml trick to make it unprivileged (mapping root to 1000), attach a filesystem using loop device to access the just-created disk image, start the container. It fails, unable to mount the disk image.
Pools test #2
- If I do the mounts manually:
mkdir /var/lib/libvirt/images/vm3/root mount /var/lib/libvirt/images/vm3/root.img /var/lib/libvirt/images/vm3/root
(note that the loop device is selected automatically) and adjust the filesystem type in libvirt type to
mount, then it starts. - If I add a second disk image for /home:
dd if=/dev/zero of=/var/lib/libvirt/images/vm3/home.img bs=1M count=1024 mkfs -t ext4 /var/lib/libvirt/images/vm3/home.img mount /var/lib/libvirt/images/vm3/home.img /mnt chown -R 1000:1000 /mnt/ umount /mnt mkdir /var/lib/libvirt/images/vm3/home mount /var/lib/libvirt/images/vm3/home.img /var/lib/libvirt/images/vm3/home virsh pool-refresh vm3
and attach the filesystem:
virt-xml vm3 --add --filesystem type=mount,source=/var/lib/libvirt/images/vm3/home,target=/home
(I think adding filesystems using virsh is not possible); this seems to work as desired:
/ # df -h Filesystem Size Used Available Use% Mounted on /dev/loop0 9.7G 2.0M 9.2G 0% / devfs 64.0K 0 64.0K 0% /dev /dev/loop1 973.4M 24.0K 906.2M 0% /home / #
- I tried to run
adduser(this is discussed in more detail below):# adduser test1 Adding user `test1' ... Adding new group `test1' (1000) ... Adding new user `test1' (1000) with group `test1' ... Creating home directory `/home/test1' ... Stopped: chown 1000:1000 /home/test1: Invalid argument
- I shut down the container, erased the contents of root and home, including dot files, but did not delete the directories themselves as they are active mountpoints, changed the owner/group back to root/root.
Back to user namespaces
Regarding the attempt above to run adduser, it looks like I need to extend the count parameter in the user namespace. Perhaps a good model would be:
start=0 target=100000 * ( <vm-index> + 1 ) count=65536
for both UID and GID mapping, where <vm-index> starts at 0. Values for count higher than 65536 are saved in the XML but shown as 65536 in virt-manager.
The container creation tools lxc-create and debootstrap create hierarchies with root@container-owned files belonging to root@host, which is suitable for a privileged container, but not for an unprivileged container, so we need a script to shift the UIDs and GIDs.
shift-uid-gid is a suitable script; be sure to read comments in it before you run it.
Back to installing an OS in the container
- I used lxc-create to create the OS container with this command:
lxc-create \ --bdev dir --dir /var/lib/libvirt/images/vm3/root -n root \ --mirror=http://deb.debian.org/debian \ -t debian -- --release=testing rm -fr /var/lib/lxc/root /var/cache/lxc/debian/rootfs-testing-amd64(For clarity, I didn’t want
lxc-createto cache the constructed root in /var/lib/lxc/<container-os>, but could not find how to disable it so justrm-ed it manually. Also, I didn’t want to use LXC directly, so removed the configuration thatlxc-createhad created.) - I downloaded the shift-uid-gid script and used it to shift the owner/group of all files in the container:
wget https://svn.pasta.freemyip.com/main/virttools/trunk/shift-uid-gid/bin/shift-uid-gid chmod 755 shift-uid-gid ./shift-uid-gid /var/lib/libvirt/images/vm3/root/ 100000 100000
- I then backed that container directory up elsewhere for later reference (see below):
rsync -a /var/lib/libvirt/images/vm3/root/ /tmp/root.lxc-create/
- I created an OS container using this root:
- username space (0,100000,65536,0,100000,65536)
- NIC plumbed into br0
- filesystem /var/lib/libvirt/images/vm3/root mapped to /
- There were a few errors during startup:
Welcome to Debian GNU/Linux 11 (bullseye)! Set hostname to . Couldn't move remaining userspace processes, ignoring: Input/output error ... systemd-journald-audit.socket: Failed to create listening socket (audit 1): Operation not permitted systemd-journald-audit.socket: Failed to listen on sockets: Operation not permitted systemd-journald-audit.socket: Failed with result 'resources'. [FAILED] Failed to listen on Journal Audit Socket. See 'systemctl status systemd-journald-audit.socket' for details. ... systemd-journald.service: Attaching egress BPF program to cgroup /sys/fs/cgroup/machine.slice/machine-lxc\x2d270139\x2dvm3.scope/system.slice/systemd-journald.service failed: Invalid argument Starting Journal Service... Starting Remount Root and Kernel File Systems... [ OK ] Mounted POSIX Message Queue File System. sys-kernel-debug.mount: Mount process exited, code=exited, status=32/n/a sys-kernel-debug.mount: Failed with result 'exit-code'. [FAILED] Failed to mount Kernel Debug File System. See 'systemctl status sys-kernel-debug.mount' for details. sys-kernel-tracing.mount: Mount process exited, code=exited, status=32/n/a sys-kernel-tracing.mount: Failed with result 'exit-code'. [FAILED] Failed to mount Kernel Trace File System. See 'systemctl status sys-kernel-tracing.mount' for details. [ OK ] Finished Helper to synchronize boot up for ifupdown. sys-kernel-config.mount: Mount process exited, code=exited, status=32/n/a sys-kernel-config.mount: Failed with result 'exit-code'. [FAILED] Failed to mount Kernel Configuration File System. See 'systemctl status sys-kernel-config.mount' for details. ... Debian GNU/Linux 11 root console root login: - I then shutdown the container, deleted the real root’s contents, changed the ownership of the mountpoint back to root:root.
- Then I installed it again, but using
debootstrap:debootstrap --verbose --variant=minbase --arch=amd64 \ --include=init,ifupdown,locales,dialog,isc-dhcp-client,netbase,net-tools,iproute2 \ --keyring=/usr/share/keyrings/debian-archive-keyring.gpg testing \ /var/lib/libvirt/images/vm3/root http://deb.debian.org/debian - I used the shift-uid-gid script to shift the owner/group of all files in the container:
./shift-uid-gid /var/lib/libvirt/images/vm3/root/ 100000 100000
- I then backed that container directory up elsewhere for later reference (see below):
rsync -a /var/lib/libvirt/images/vm3/root/ /tmp/root.debootstrap/
- The errors during startup appeared to be the same as above.
- I used FAD to compare the backup of the
lxc-create-created root and thedebootstrap-created root; the main differences were:lxc-createconfigured the NIC to use DHCP; debootstrap left the NIC unconfiguredlxc-createadded security to /etc/apt/sources.listlxc-createinstalled openssh-server (plus prerequisites), /etc/inittab, getty startup on several VTs, sensible-utils
- I recreated the root again using debootstrap with some slight modifications:
debootstrap --verbose --variant=minbase --arch=amd64 \ --include=init,ifupdown,locales,dialog,isc-dhcp-client,netbase,net-tools,iproute2,openssh-server,sensible-utils \ --keyring=/usr/share/keyrings/debian-archive-keyring.gpg testing \ /var/lib/libvirt/images/vm3/root http://deb.debian.org/debian echo -e 'auto lo\niface lo inet loopback\n\nauto eth0\niface eth0 inet dhcp' > /var/lib/libvirt/images/vm3/root/etc/network/interfaces - Then, as before, I did the UID/GID shift, backed it up, started the container (the errors during startup appeared to be the same as above) and finally used FAD to compare the backup of the
lxc-create-created root and this seconddebootstrap-created root; there were much much fewer differences (and now I could see some that I must have missed the first time):lxc-createconfigured /etc/hostname correctly; debootstrap reused the host’s hostnamelxc-createcreated /etc/inittab (spawning multiple getty processes)
Conclusions #2
- I should use lxc-create to create an OS container, rather than using debootstrap, because:
- it leaves me with fewer commands to run manually
- it offloads investigative work from me
Recap
Regarding this procedure, note:
- the repeated mount/umount, this is done to (a) make the steps reentrant, (b) make clear that the final start/stop requires then mount/umount
- Set some variables:
export LIBVIRT_DEFAULT_URI=lxc:/// # make sure virsh understands to create LXC VMs not KVM VMs NAME=vm4 UID_GID_SHIFT=200000 ROOT_PASSWORD=xxxxxxxx # set to desired root password for container
- Get some scripts we’ll need:
mkdir -p ~/opt svn co https://svn.pasta.freemyip.com/main/virttools/trunk ~/opt/virttools
- Create the pool and start it:
lvcreate --size=15g --name=$NAME vg1 mkfs -t ext4 /dev/vg1/$NAME # don't contaminate default pool with pools! mkdir -p /var/lib/libvirt/pools/$NAME virsh pool-define-as --name $NAME --type fs --source-dev /dev/vg1/$NAME --target /var/lib/libvirt/pools/$NAME virsh pool-start $NAME
- Create and populate the root volume (including setting root’s password):
dd if=/dev/zero of=/var/lib/libvirt/pools/$NAME/root.img bs=1M count=5120 mkfs -t ext4 /var/lib/libvirt/pools/$NAME/root.img mkdir /var/lib/libvirt/pools/$NAME/root mount /var/lib/libvirt/pools/$NAME/root.img /var/lib/libvirt/pools/$NAME/root lxc-create \ --bdev=dir \ --dir=/var/lib/libvirt/pools/$NAME/root \ --name=$NAME \ --template=debian \ -- \ --mirror=http://deb.debian.org/debian \ --release=testing echo -e "$ROOT_PASSWORD\n$ROOT_PASSWORD" | \ chroot /var/lib/libvirt/pools/$NAME/root passwd root umount /var/lib/libvirt/pools/$NAME/root rm -fr /var/lib/lxc/$NAME rm -fr /var/cache/lxc/debian/rootfs-testing-amd64 - Shift the owner/groups:
mount /var/lib/libvirt/pools/$NAME/root.img /var/lib/libvirt/pools/$NAME/root ~/opt/virttools/shift-uid-gid/bin/shift-uid-gid /var/lib/libvirt/pools/$NAME/root $UID_GID_SHIFT $UID_GID_SHIFT umount /var/lib/libvirt/pools/$NAME/root
- Define the basic container:
virsh define <(~/opt/virttools/create-basic-lxc-vm/bin/create-basic-lxc-vm $NAME $UID_GID_SHIFT)
- To add a /home volume run:
dd if=/dev/zero of=/var/lib/libvirt/pools/$NAME/home.img bs=1M count=1024 mkfs -t ext4 /var/lib/libvirt/pools/$NAME/home.img mkdir /var/lib/libvirt/pools/$NAME/home mount /var/lib/libvirt/pools/$NAME/home.img /var/lib/libvirt/pools/$NAME/home ~/opt/virttools/shift-uid-gid/bin/shift-uid-gid /var/lib/libvirt/pools/$NAME/home $UID_GID_SHIFT $UID_GID_SHIFT virt-xml $NAME --add --filesystem type=mount,source=/var/lib/libvirt/pools/$NAME/home,target=/home umount /var/lib/libvirt/pools/$NAME/home
- Start the container with:
mount /var/lib/libvirt/pools/$NAME/root.img /var/lib/libvirt/pools/$NAME/root mount /var/lib/libvirt/pools/$NAME/home.img /var/lib/libvirt/pools/$NAME/home virsh start $NAME
- Log in as root on the console and do a simple network check with:
timeout 10 cat > /dev/tcp/www.google.com/80 exit
(Not much is installed yet, not even ping, so a more sophisticated check will have to wait.)
- Shut the container down with:
virsh shutdown $NAME umount /var/lib/libvirt/pools/$NAME/root umount /var/lib/libvirt/pools/$NAME/home
- Shut the pool down:
virsh pool-destroy $NAME
Boot-time error messages
During container startup:
- a kernel bug logged as a systemd bug causes this:
Couldn't move remaining userspace processes, ignoring: Input/output error
- a systemd bug causes this and some related error messages:
systemd-journald-audit.socket: Failed to listen on sockets: Operation not permitted
- another systemd bug causes these:
sys-kernel-debug.mount: Mount process exited, code=exited, status=32/n/a sys-kernel-debug.mount: Failed with result 'exit-code'. [FAILED] Failed to mount Kernel Debug File System. See 'systemctl status sys-kernel-debug.mount' for details. sys-kernel-tracing.mount: Mount process exited, code=exited, status=32/n/a sys-kernel-tracing.mount: Failed with result 'exit-code'. [FAILED] Failed to mount Kernel Trace File System. See 'systemctl status sys-kernel-tracing.mount' for details. sys-kernel-config.mount: Mount process exited, code=exited, status=32/n/a sys-kernel-config.mount: Failed with result 'exit-code'. [FAILED] Failed to mount Kernel Configuration File System. See 'systemctl status sys-kernel-config.mount' for details.
but these can be addressed by running:
systemctl mask sys-kernel-debug.mount systemctl mask sys-kernel-trace.mount systemctl mask sys-kernel-config.mount
Hooks #1
At this point I discovered hooks and arbitrary per-app metadata, which might allow virsh start to mount the disk images inside the pool or even to revert to using block devices as volumes!
Let’s start simple! In the ‘Recap’ section above, the container is started with:
virsh pool-start $NAME mount /var/lib/libvirt/pools/$NAME/root.img /var/lib/libvirt/pools/$NAME/root mount /var/lib/libvirt/pools/$NAME/home.img /var/lib/libvirt/pools/$NAME/home virsh start $NAME
and stopped with a symmetric stanza. I want:
- the mounts and umounts to be done in a hook
- maybe to use non-VM-specific pools (meaning that I decouple pool start/stop from container start/stop)
So I wrote an lxc hook called mounter that looks for mounter’s metadata in the VM’s XML and acts upon it.
- I should have already downloaded virttools; if not then see above.
- Hardlink the mounter plugin:
cd /etc/libvirt/lxc.d/ ln ~/opt/virttools/libvirt-hooks/lxc.d/mounter
Note that symlinking won’t work (error message normally appears all on one line):
testaroli# virsh start $NAME error: Failed to start domain 'vm4' error: Hook script execution failed: internal error: Child process (LC_ALL=C PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin /etc/libvirt/hooks/lxc.d/mounter vm4 prepare begin -) unexpected exit status 126: libvirt: error : cannot execute binary /etc/libvirt/hooks/lxc.d/mounter: Permission denied testaroli#
- Edit the VM’s XML by running:
virsh edit $NAME
and add:
<uuid>...</uuid> <metadata> <app1:mounter xmlns:app1="http://app1.org/app1/"> <mounts> <mount type="loop" device="/var/lib/libvirt/pools/vm4/root.img" mntpnt="/var/lib/libvirt/pools/vm4/root"/> <mount type="loop" device="/var/lib/libvirt/pools/vm4/home.img" mntpnt="/var/lib/libvirt/pools/vm4/home"/> </mounts> </app1:mounter> </metadata> <memory unit='KiB'>...</memory>Note that I could not find an virt-xml command to insert that from the command line.
- The VM can now be started and stopped with only:
testaroli# export LIBVIRT_DEFAULT_URI=lxc:/// testaroli# NAME=vm4 testaroli# virsh pool-start $NAME Pool vm4 started testaroli# virsh start $NAME Domain 'vm4' started testaroli# virsh shutdown $NAME Domain 'vm4' is being shutdown testaroli# virsh pool-destroy $NAME Pool vm4 destroyed testaroli#
Woohoo!
Pools
However, judging by examples, it looks like there are conventions:
- multiple volumes may carved out of a single pool and attached to different VMs
- pools provide storage of a “class”, where the class relates to the nature/name/whatever of the underlying storage, not on the nature/name/whatever of the VMs that use storage from that pool
DRBD sounds like a storage class and therefore sounds a suitable candidate to make a storage pool out of.
However, if I allocated one DRBD to a new storage pool and then put two VMs’ volumes in that pool then, migrating only one of the VMs:
- would require OCFS/2 (which I found added a substantial performance overhead and very prone to lockups leading to split brain), or
- another clustered filesystem (which all have more complicated resource managers), or
- I abuse storage pools by limiting their contents to the volumes for only one VM (which goes against the conventions), or
- I don’t use pools
The latter is what I currently do and is accepted in the official documentation:
Storage pools and volumes are not required for the proper operation of VMs … but some administrators will prefer to manage their own storage and VMs will operate properly without any pools … On systems that do not use pools, system administrators must ensure the availability of the VMs’ storage using whatever tools they prefer ….
So I will continue to not use pools.
testing DRBD-based container environment
The main aims of this section are:
- the hook script needs to be extended to handle DRBD devices and/or generic block devices; the difference would be a call to
drbdadm primary - I want to test my scripts for creating VMs, as I have moved a lot of scripts recently
- I want to do DRBD-based tests
So here I go:
- I modified the hook script to change the ‘loop’ type to use parameters ‘file’ (instead of ‘device’) and ‘mntpnt’
- I modified vm4’s metadata accordingly and tested.
- I modified the hook script to add a ‘block’ type to use parameters ‘device’ and ‘mntpnt’.
- I configured pestaroli the same as testaroli in PCMS (to prepare for installing pestaroli)
- I released a new PCMS (to clear the badly formatted messages coming from other hosts and to make reinstalling testaroli cleaner)
- I shut down testaroli, backed up its disk images and deleted them
- I shut down pestaroli, didn’t back up its disk images and deleted them
- I recreated the disk images as follows:
fiori# ~/opt/virttools/bin/create-perfect-drbd-vol -v --run-remote testaroli 20 192.168.3.6 192.168.3.7 fiori# ~/opt/virttools/bin/create-perfect-drbd-vol -v --run-remote testaroli_containers 80 192.168.3.6 192.168.3.7 fiori# ~/opt/virttools/bin/create-perfect-drbd-vol -v --run-remote pestaroli 20 192.168.3.6 192.168.3.7 fiori# ~/opt/virttools/bin/create-perfect-drbd-vol -v --run-remote pestaroli_containers 80 192.168.3.6 192.168.3.7
(Ordinarily, I would not wait for the DRBD syncs to complete, but it was near the end of the day and four of them added load to the systems, so I let it run overnight. Also: I realise this means I will have four copies of the contains I put on the containers DRBD device; I don’t care, I want an accurate test eivironment.)
- I modified the two VM creator scripts to load msg.sh
- create the pestaroli and testaroli VMs, initially with only one disk (as per what the script expects) by running:
fiori# create-perfect-kvm-vm -v --run-remote pestaroli block:/dev/drbd_pestaroli torchio fiori# create-perfect-kvm-vm -v --run-remote testaroli block:/dev/drbd_testaroli torchio
- At this point I made a slight digression: I wanted pestaroli and testaroli to replicate over the replication network, not over the public network, but both fiori and torchio have eth1 configured with an IP, rather than being used as a bridge device, so I did the following on both fiori and torchio (though not in parallel):
- saved all file/web edits
- migrated all running VMs to the other host
- reconfigured eth1 as br1 using eth1
- rebooted
- I installed Debian 11 on pestaroli and testaroli, including tailoring and running PCMS.
- I installed packages: lxc, libfile-lchown-perl (needed by shift-uid-gid), libvirt-daemon-driver-lxc (
systemctl restart libvirtdneeded afterwards), xmlstarlet - I shutdown both VMs and:
- I added the /dev/drbd_<vm>_containers storage to pestaroli and testaroli.
- I added a second interface on the replication network and configure it (actually, I had to do this before running PCMS as it expected the 2nd NICs to exist)
- I added corresponding entries to DNS
- I increased memory to 4GB
- I restarted the the VMs
- I set up the new disk device for use by DRBD:
apt-get -y install drbd-utils pvcreate /dev/vdb vgcreate vg1 /dev/vdb
- I added a new mail server name (mafalde) to DNS
- I set up ssh access between the nodes
- I created an 20GB DRBD device out of that storage by running:
create-perfect-drbd-vol -v --run-remote mafalde 20 192.168.3.31 192.168.3.32
- In CheckMK, I refreshed the list of services to monitor on pestarol and testaroli.
- Regarding where container-specific devices will be mounted (using the hook):
- I could find no suggestions on the web, so decided upon /var/lib/libvirt/mountpoints
- On both pestaroli and testaroli, I checked out the module containing the hook and hooked it in as follows:
mkdir -p ~/opt svn co https://svn.pasta.freemyip.com/main/virttools/trunk ~/opt/virttools mkdir -p /etc/libvirt/hooks/lxc.d ln ~/opt/virttools/bin/etc-libvirt-hooks-lxc.d-mounter /etc/libvirt/hooks/lxc.d/mounter
(As above, the link must be a hardlink, not a symlink.)
- Create the container by running:
drbdadm primary drbd_mafalde create-basic-lxc-vm -v --remote=testaroli mafalde /dev/drbd_mafalde 100000
- Start the container with:
virsh --connect=lxc:/// start mafalde
- I modified vm-list and vm-migrate to support LXC, msg.sh, pestaroli/testaroli.
- I used vm-migrate migrate mafalde backwards and forwards.
- Prior to setting up PCMS I installed a few packages that were missing and that the PCMS procedure expected to already be there. The installation of these packages could become part of the installing-a-container procedure or a part of the installing-pcms procedure
- vim: needed to edit /etc/ssh/sshd_config; PCMS page also says to install it
- wget: needed to download svn-cache-passwd
- apt-utils: pcms calls apt-get, which constantly complains:
debconf: delaying package configuration, since apt-utils is not installed Selecting previously unselected package apt-utils.
- xterm: useful as contains resize, which is useful for serial terminal (LXC console)
- PCMS the container first as just a dumb server according to Installing and running PCMS.
- Disable various mounts that won’t work in containers:
systemctl mask sys-kernel-debug.mount systemctl mask sys-kernel-tracing.mount systemctl mask sys-kernel-config.mount systemctl mask systemd-journald-audit.socket
- I saw there was no syslog process inside the container, so installed rsyslogd.
- I submitted bug report BTS#991773, regarding attempts to reboot a container shutting in down instead.
Misaligned packaged lists
- There are a lot of differences between the list of packages on pestaroli and on mafalde. Why? Here’s the list:
pestaroli# comm -1 -3 <(dpkg -l | sed -nr -e '1,5d' -e 's/^ii ([^ ]+).*/\1/p' | sort) <(chroot /var/lib/libvirt/mountpoints/mafalde/root dpkg -l | sed -nr -e '1,5d' -e 's/^ii ([^ ]+).*/\1/p' | sort) | egrep -v '^(lib|lxc|grub)' dialog fontconfig fonts-droid-fallback fonts-noto-mono fonts-urw-base35 ghostscript groff gsfonts hicolor-icon-theme imagemagick imagemagick-6-common imagemagick-6.q16 mesa-vulkan-drivers:amd64 netpbm poppler-data psutils systemd-timesyncd x11-utils pestaroli# comm -2 -3 <(dpkg -l | sed -nr -e '1,5d' -e 's/^ii ([^ ]+).*/\1/p' | sort) <(chroot /var/lib/libvirt/mountpoints/mafalde/root dpkg -l | sed -nr -e '1,5d' -e 's/^ii ([^ ]+).*/\1/p' | sort) | egrep -v '^(lib|lxc|grub)' apt-listchanges arch-test augeas-lenses bash-completion bind9-dnsutils busybox-static cloud-image-utils console-setup console-setup-linux cron debconf-i18n debian-faq debootstrap discover discover-data distro-info dnsmasq doc-debian drbd-utils efibootmgr fakechroot fakeroot fdisk firmware-linux-free genisoimage gpm iamerican ibritish ienglish-common initramfs-tools initramfs-tools-core installation-report ipxe-qemu isc-dhcp-common iso-codes ispell kbd keyboard-configuration keyutils klibc-utils krb5-locales laptop-detect linux-base linux-image-5.10.0-7-amd64 linux-image-5.10.0-8-amd64 linux-image-amd64 mailcap manpages mime-support mmdebstrap mokutil nano ncurses-term netcat-openbsd netcat-traditional nfs-common ntp ntpdate os-prober ovmf python3-debconf qemu-guest-agent qemu-system-common qemu-system-data qemu-system-x86 qemu-utils rpcbind seabios shim-helpers-amd64-signed shim-signed-common shim-signed:amd64 shim-unsigned systemd-container task-english tasksel tasksel-data uidmap util-linux-locales vim-tiny wamerican whiptail xauth xkb-data xmlstarlet pestaroli#
- Actually, it is not so bad, if I go back to pre-PCMS-ed systems, the the KVM system not install any tasksel groups then:
- I installed openssh-server on the KVM system
- I installed vim on the LXC system
- I installed debfoster on both
- I ran debfoster answers ‘yes’ to all packages and then diffed as follows (192.168.1.156 is KVM and 192.168.1.157 is LXC):
lagane$ # only on KVM lagane$ comm -2 -3 <(ssh root@192.168.1.156 sort /var/lib/debfoster/keepers) <(ssh root@192.168.1.157 sort /var/lib/debfoster/keepers) X11 forwarding request failed on channel 0 console-setup discover eject grub-efi-amd64 installation-report libreadline8 linux-image-5.10.0-7-amd64 linux-image-amd64 lvm2 qemu-guest-agent task-english usbutils whiptail lagane$ # only on LXC lagane$ comm -1 -3 <(ssh root@192.168.1.156 sort /var/lib/debfoster/keepers) <(ssh root@192.168.1.157 sort /var/lib/debfoster/keepers) X11 forwarding request failed on channel 0 dialog locales lagane$
- Things to explain are:
- why is libreadline8, task-english, qemu-guest-agent, usbutils, whiptail on the KVM system?
- why is dialog and locales on the LXC system? I think lxc-create might install these?
- the rest are hardware or kernel related and therefore not appropriate to a container.
- Explanations/response:
- locales is on both systems, but it gets pulled in as a dependency on KVM one and not on LXC (I think lxc-create command installs it explicitly)
- whiptail and dialog are functionally the same; presumably not all packages are aligned in what they prerequire
- KVM: remove libreadline8 and taskenglish
- LXC: install whiptail; remove dialog
- Both XXX and YYY have been updated with tese instructions.
- I did another loop of package comparison:
- I installed the container and KVM VM installation following the instructions at Installing Debian 11 on a PM or KVM VM and Installing Debian 11 on an LXC container.
- I configured sshd_config to allow root login with password
- Used
ip -o -4to get the IP addresses - Use
ssh-copy-idto copy alexis@lagane’s key to root@ each host - On both systems installed debfoster (that this is missing is not a misalignment because it is missing on both, but I need it for doing the checks)
- Ran
debfoster -qon both hosts - Compared package lists from lagane:
lagane$ comm -2 -3 <(ssh root@192.168.1.159 sort /var/lib/debfoster/keepers) <(ssh root@192.168.1.158 sort /var/lib/debfoster/keepers) console-setup discover eject grub-efi-amd64 installation-report linux-image-5.10.0-7-amd64 linux-image-amd64 lvm2 qemu-guest-agent usbutils util-linux-locales lagane$ comm -1 -3 <(ssh root@192.168.1.159 sort /var/lib/debfoster/keepers) <(ssh root@192.168.1.158 sort /var/lib/debfoster/keepers) net-tools whiptail lagane$
Note that, in this particular loop, the KVM VM got the higher IP by DHCP when before it had got the lower.
- I considered integrating these next steps into PCMS:
- Disable various mounts that won’t work in containers:
systemctl mask sys-kernel-debug.mount systemctl mask sys-kernel-tracing.mount systemctl mask sys-kernel-config.mount systemctl mask systemd-journald-audit.socket
- Align the set of installed packages with a common PM/KVM-VM/LXC baseline (see here for more details) by running:
apt-get --no-install-recommends install whiptail vim rsyslog apt-get --purge autoremove dialog
but in the end decided not to.
- Disable various mounts that won’t work in containers: